Index a folder of multilanguage documents in Solr with Tika
Previous Posts on the serie
- Import folder of Documents with Apache Solr 4.0 and Tika
- Highlight matched test inside documents indexed with Solr And Tika
Everything is up and running, but now requirements change, documents can have multiple languages (italian and english in my scenario) and we want to do the simplest thing that could possibly work. First of all I change the schema of the core in solr to support language specific fields with wildcards.

Figure 1: Configuration of solr core to support multiple language field.
This is a simple modification, all fields are indexed and stored (for highlighting) and multivalued. Now we can leverage another interesting functionality of Solr+Tika, an update handler that identifies the language of every document that got indexed. This time we need to modify * solrconfig.xml *file, locating the section of the /update handler and modify in this way.
| |
I use a TikaLanguageIndentifierUpdateProcessorFactory to identify the language of documents, this runs for every documents that gets indexed, because it is injected in the chain of UpdateRequests. The configuration is simple and you can find full details in solr wiki. Basically I want it to analyze both the title and content field of the document and enable mapping of fields. This means that if the document is detected as Italian language it will contain content_it and title_it fields not only content field. Thanks to previous modification of solr.xml schema to match dynamicField with the correct language all content_xx files are indexed using the correct language.
This way to proceed consumes memory and disk space, because for each field I have the original Content stored as well as the content localized, but it is needed for highlighting and makes my core simple to use.
Now I want to be able to do a search in this multilanguage core , basically I have two choices:
- Identify the language of terms in query and query the correct field
- Query all the field with or.
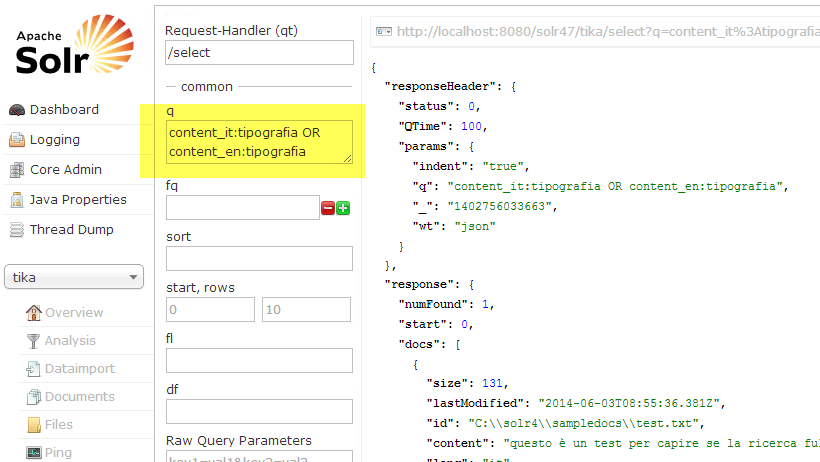
Since detecting language of term used in query gives a lots of false positive, the secondo technique sounds better. Suppose you want to find italian term “tipografia”, You can issue query: * content_it:tipografia OR content_en:tipografia.*Everything works as expected as you can see from the following picture.
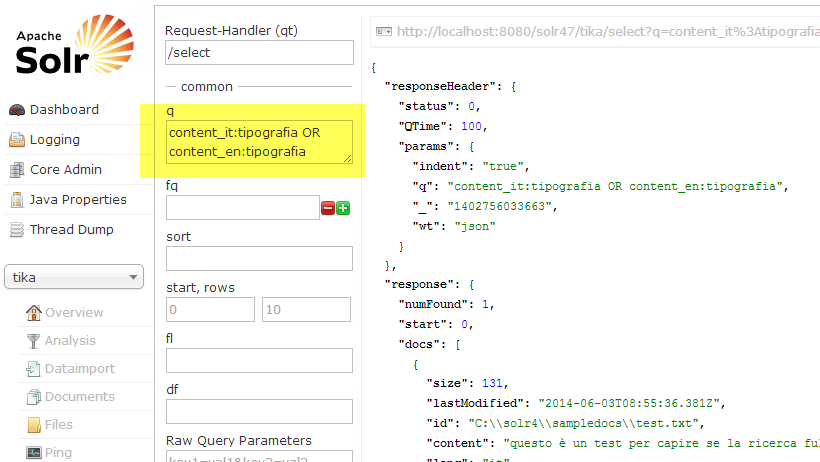
Figure 2: Sample search in all content fields.
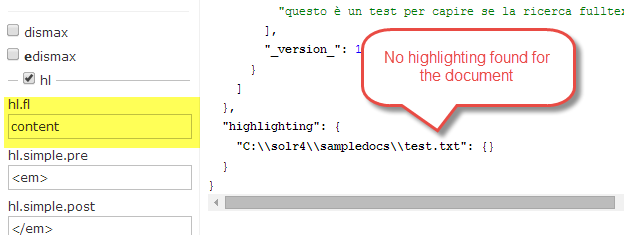
Now if you want highlights in the result, you must specify all localized fields , you cannot simply use Content field. As an example, if I simply ask to highlight the result of previous query using original content field, I got no highlight.
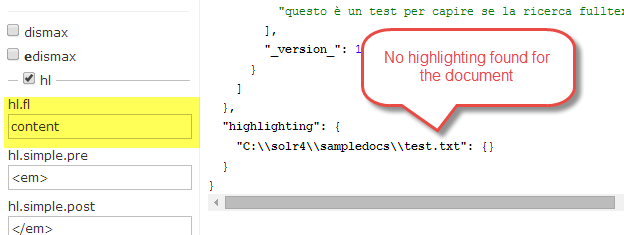
Figure 3: No highlighting found if you use the original Content field.
This happens because the match in the document was not an exact match, I ask for word tipografia but in my document the match is on the term *tipografo,*thanks to language specific indexing Solr is able to match with stemming, this a typical full text search. The problem is, when is time to highlight, if you specify the content field, solr is not able to find any match of word tipografia in it, so you got no highlight.
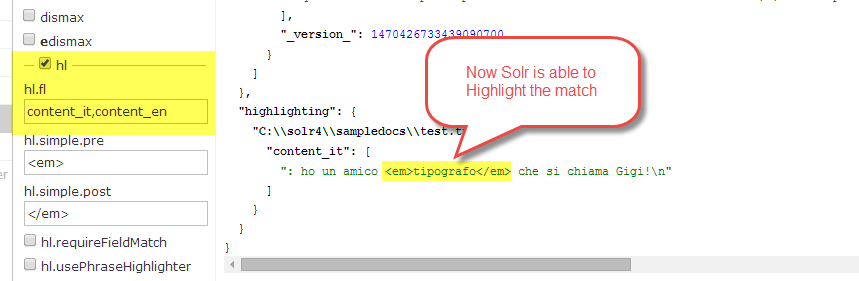
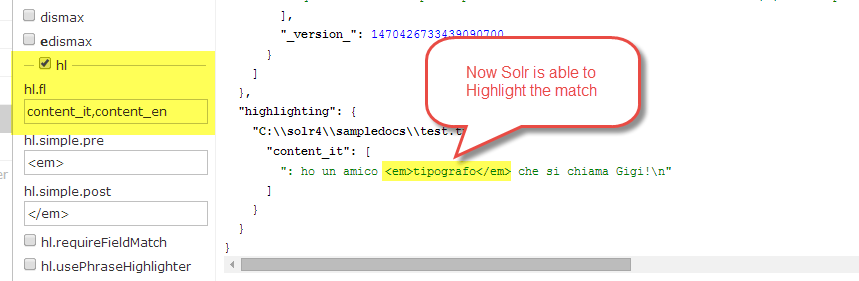
To avoid problem, you should specify all localized fields in hl parameters , this has no drawback because a single document have only one non-null localized field and the result is the expected one:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 4: If you specify localized content fields you can have highlighting even with a full-text match.
In this example when is time to highlight Solr will use both content_it and content_en. In my document content_en is empty, but Solr is able to find a match in content_it and is able to highlight with the original content, because content_it has stored=”true” in configuration.
Clearly using a single core with multiple field can slow down performances a little bit, but probably is the easiest way to deal to index Multilanguage files automatically with Tika and Solr.
Gian Maria.