Hilight matched text inside documents indexed with Solr plus Tika
I’ve already dealt on how to index documents with Solr and Tika and in this article I’ll explain how you can not only search for documents that match your query, but returns even some text extract that shows where the document match the query. To achieve this, you should store the full content of the document inside your index, usually I create a couple of fields, one called Content that will contain the content of the file, and with a copyfield directive ( <copyField source=”content” dest=”text”/> ) automatically copy that value inside the catch all field called text.
| |
Text field is multivalued and not stored, it is only indexed to permit search inside various field of the document. Content field store the extracted text from Tikaand it is useful both for highlighting and to troubleshoot extraction problems, because it contains the exact text extracted by Tika.
Now suppose you want to search for the term Branch and want also to highlight the part of the text where you find that term , you can simply issue a query that ask for highlighting, it is really simple.
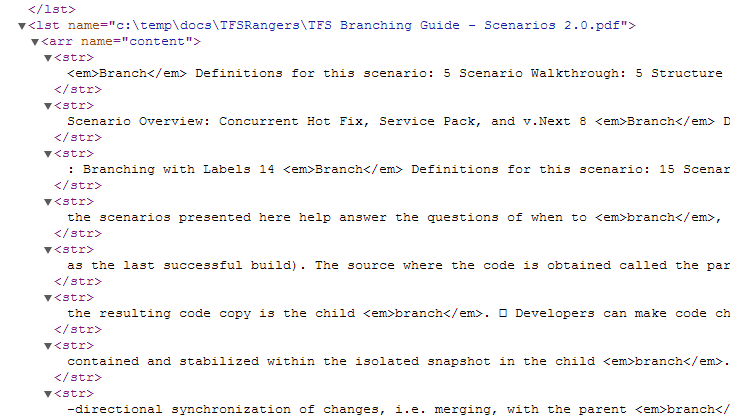
This simple query ask for document with text that contains word branch, I want to extract (fl=) only title and author fields, want xml format and with hl=true I’m asking for snippet of matching text, hl.snippets=20 instruct solr to search for a maximum of 20 snippet and hl.usePhraseHighlighter=true use a specific highlighter that try to extract a single phrase from the text. The most important parameter is the hl.fl=content that specify the field of the document that contains the text used for highlight. In the results, after all matching documents there is a new section that contains all the highlights for each document
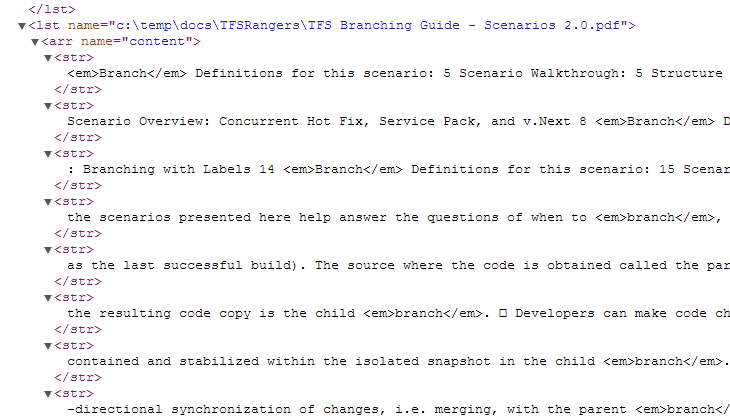
Figure 1: Hilight for the TFS Branching Guid – Scenarios 2.0.pdf file
The name of the element match the id of the document (in my configuration full path of the file), and there a list of highlights that follows. But the true power of Solr comes out if you start to use languages specific fields.
| |
I’ve just changed in schema.xml the type of Content and Text from general_text to text_en and this simple modification enables a more specific tokenizer, capable of doing full-text searches. Suppose you want to know all documents that deal with branching strategies, here is a possible query
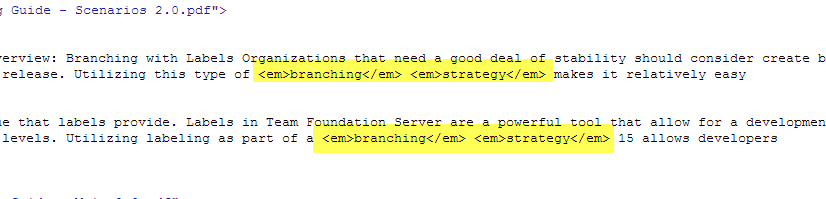
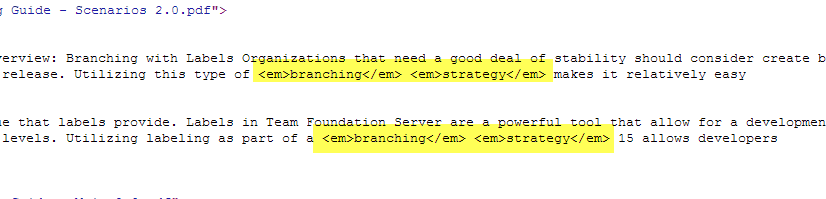
The key is in the search query text:”branch strategy”~3 that states I’m interested in documents containing both branch and strategy terms and with a relative distance of no more than three words. Since text was indexed with text_en field type I got full-text search, and I have a confirmation looking at the highlights.
{kind=link}
{kind=link}
Figure 2: Highlights for a proximity query with full text, as you can see word branching matches even if I searched for branch
And voilà!! You have full-text searching inside file content with minimal amount of work and a simple REST interface for querying the index
Gian Maria.