Case sensitivity in lucene search
- Getting Started With Lucene.NET
- Searching and more detail on Documents Fields
- Advanced Queries with Lucene.NET
We ended last post with a good knowledge of how to do complex searches in Lucene.NET indexes but a question remains unresolved, is Lucene.NET search case insensitive or case insensitive?. Suppose you search for
+mime + format
Here is the first result returned from the above query.

Figure 1: Searching for +mime +format returns a document that contains MIME in uppercase.
As you can see this documents satisfy the query with the word MIME, thus suggesting that the query is Case Insensitive (you searched for mime but MIME satisfied the search), but this is not true. If you look at Lucene documentation you can find that all searches are always case sensitive , and there is no way to do case insensitive search. This fact usually puzzled the user because searches seems to be Case insensitive, so where is the trick?. The answer is: StandardAnalyzer transforms in lowercase all the tokens before storing them into the index and QueryParser lowercase all the terms during query parsing.
{kind=link}
{kind=link}
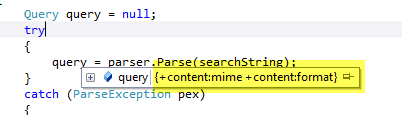
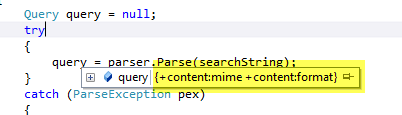
Figure 2: The query resulted from the parsing of +MIME +FORMAT
As you can see in * Figure 2 *I’ve showed the result of parsing the query +MIME +FORMAT; the result correctly has the default field contentbefore each search term, but it also present every term in lowercase. If you look closely at the constructor of QueryParser you can verify that it needs a reference to the analyzer used to create the index. During initialization QueryParser ask to that analyzer if he manipulate tokens before storing them to the index to apply the very same manipulation to search terms during query parsing. If you manually create a query to issue a search for term MIME (all uppercase) with this simple line of code you can be surprised by the result.
| |
The index does not return a single result even if the previous query showed in Figure 1 that the word MIME is present in the original text. The reason is: **StandardAnalyzer converted every term in lowercase so the index contains term mime not MIME and the above query has no result **. This example shows how important is to initialize the QueryParser with the very exact Analyzer class type or you can incur in really bad surprise.
To build a Case Sensitive index you can simply create your own analyzer, inheriting from StandardAnalyzer and overriding the TokenStream method
| |
The code inside TokenStream() method is similar to the one contained in StandardAnalyzer and shows clearly its default configuration. The** TokenStream is a specific stream that permits to “tokenize” the content**to split words from the original content. For a StandardAnalyzer the base tokenizer is of type StandardTokenizer a grammar enabled tokenizer, capable to recognize specific patterns of english language. In the second line the the StandardTokenizer is used as base stream for a StandardFilter that is used to handle standard punctuation like aphostrophe or dots. As you can see each new Stream is created passing the previous one as a source to build a chain of filters that gets applied to tokens one after another. The third line was commented in my analyzer because it is the one that adds the LowerCaseFilter, used to transform each token to lowercase and finally the StopFilter remove some noise words that should not be indexed because are known to be noise in the English language. If you comment the line that adds the LowerCaseFilter, all the tokens will be stored inside the index with original casing obtaining a Case Sensitive index. If you need to support case sensitive and case insensitive search in the same application, you need to build two different indexes in two distinct folders and use the right one during searches.
With this Analyzer I created another index of the first five million post of the dump of StackOverflow, then I issued the query +Mime +Format , obtaining this result:
*Insert search string:+Mime +Format
N°4 found in 9 ms. Press a key to look at top results*
As you can see, searching for +Mime +Format returns only 4 resultsw, because now the search was case sensitive so words like MIME does not satisfy the query. The cool part is that QueryParser correctly identifies that our new analyzer does not apply the LowerCaseFilter so it does not lowercase terms during query parsing. This example shows how you can manage search casing with lucene and gave you some golden rule:
Rule #1: all lucene searches are case sensitive, if you build query directly with TermQuery class you need to be aware of casing used by the analyzer.
Rule #2: standard analyzer applies a lowercase filter to tokens to make search case insensitive.
Rule #3: if you need a Case Sensitive search ,you need to create an index with an Analyzer that does not apply lowercase to tokens, such as the above CaseSensitiveStandardAnalyzer
Rule #4: always pass to QueryParser constructor the very same type of Analyzer used to create the index, because QueryParser needs it to determine if search terms should be lowercased to build the query.
Happy searching :)
Gian Maria.