Using guid id in nhibernate index fragmentation
This is a quick consideration about using id of type GUID in nhibernate. If in SQL server the cluster index is on the id (default choiche), if you use a simple guid generator you will end in high index fragmentation. This happens because if you insert a lot of objects into the table, since the physical ordering of the records (the clustered index) is on the Id field, inserting a sequence of objects with random id will insert these object randomly into the physical space of the DB. Remember that the index is a Tree that was kept ordered by its clustered index.

Figure 1: A simple picture that shows the index organization in a database.
A simple solution is using guid.comb generator
| |
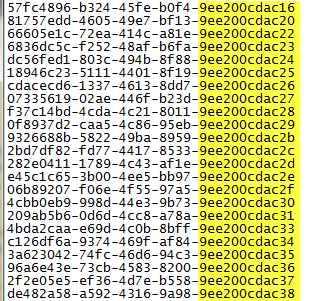
And look at generated guid when I insert a bunch of elements in unit test.
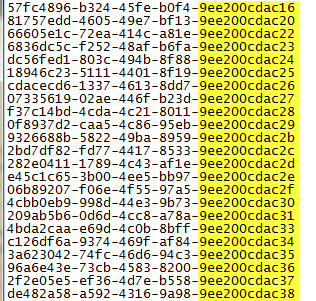
Figure 2: The id sequence generated by guid.comb generator
As you can see, it is quite clear that guid are generated sequentially, but the very first part is highly different, so it seems to me that those guid are really not so similar. Another problem is that I hate guid for human readability and inserting a sequence of elements results in highly different guid. The solution is using another guid generation strategy
| |
This function permits me to use the UuidCreateSequential operating system function to generate a sequential guid. Now you can write another nhibernate generator.
| |
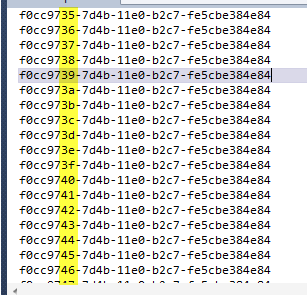
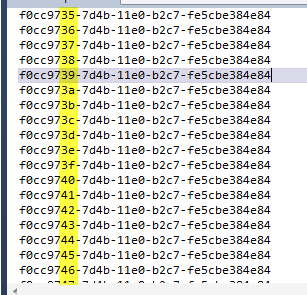
Now I change the id generator and run again the test.
{kind=link}
{kind=link}
Figure 3: Sequential guid generator are much more equals.
As you can verify now guid are really similar each ones, and I highlighted only the part that is different. This generator can reduce indexes fragmentation, and sequentially inserted element are really simple, because they differ only for few digit, and in my opinion this lead to a better human readability.
Clearly performance consideration are valid only when the clustered key is on the id, if clustered index is on other fields, all consideration about performance of guid should be not taken into consideration.
Alk.